
상관분석(correlation analysis) : 관련있는 두 변수간의 관련성을 통계적으로 분석하는 것으로 본격적으로 두 변수의 관련성을 가지고 회귀분석에 들어가기 전에 자료를 정비하는 것
상관분석의 단계
- 두 변수간의 상관성을 눈으로 산점도 작성
- 두 변수간의 상관성을 수치화
- 상관계수가 통계적으로 유효한지 검정
1. 산점도 작성
- 상관관계의 종류 : 양의 관계, 음의 관계, 무 관계, 곡선 관계(예를 들어 양의 상관관계였다가 음의 상관관계로 변하는 관계), 절대 상관 관계(완벽하게 직선상에 데이터 있는 경우)
- 이상점(outlier)를 발견 가능
- 층별 을 이루는가를 확인 할 수 있다(층별이 관측되었을 때 분리해서 분석을 해야 하지 않나라고 판단할 수 있다).
2. 상관 관계의 수치화
- 상관계수(correlation coefficient) : 두 변수의 관계를 하나의 수치로 나타낸 척도


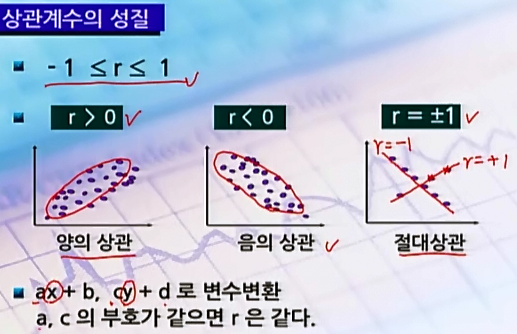
- r= 0 이라고 해서 꼭 무상관은 아니다. 곡선 관계일수도 있기 때문에 꼭 산점도를 그래서 확인하는 것이 좋다. 그리고 이상치의 유무를 확인하기 위해서도 산점도는 필요하다.
혼돈요인(confounding factor) : 숨은 변수. 이 변수를 놓치면 분석시 잘못된 결론을 내릴 수 있다.
심슨 파라독스(Simpson's Paradox) : 자료분석 시 숨은 변수, 컨파운딩 팩터를 놏치면 반대의 결론을 내게 됨, 예를 들어 학생들의 전체를 놓고 분석했을때 tv 시청과 읽기 능력의 양의 상관관계가 있는 것처럼 보였으나 학년 별로 그룹핑을 해서 상관분석을 해보니 학년 내에서는 음의 상관관계가 있는 것으로 나타났다.
3. 상관계수의 유의점 점검










